Conceitos do Engine
Introdução
O Engine é um aplicativo executável nativo e é a base da plataforma Nginstack. Ele e suas bibliotecas são desenvolvidas em C++, Rust e Object Pascal, adotando uma arquitetura híbrida de servidor e cliente, onde o Engine tanto pode ser instalado como servidor principal de aplicação, como também pode ser instalado como um servidor de borda ou em uma estação de usuário, reduzindo a latência de comunicação e permitindo a distribuição da carga de processamento. Seus principais componentes são:
- Servidor Web (HTTP);
- Cache de diversas tabelas do banco de dados;
- Interpretador JavaScript;
- Sistema de arquivos virtual e embarcado;
- Editor e depurador de códigos;
- Protocolo de comunicação Engine (IAP);
- Ferramentas para instrumentação e análise de desempenho;
- Interface para análise de concorrência e consumo de memória;
- Objetos facilitadores de acesso e manipulação do banco de dados;
O Engine possui ainda uma integração com a Java J2SE, comumente usado para a criação e consumo de WebServices. O acesso aos SGBDs é feito através de drivers criados especificamente para cada banco. Hoje o Engine suporta os bancos Oracle, MSSQL Server e PostgreSQL.
A arquitetura do Engine
O infográfico abaixo representa a arquitetura do Engine.
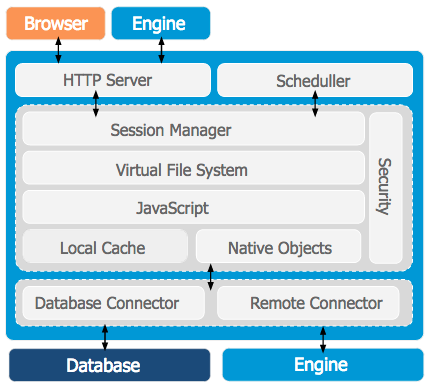
Note que o servidor HTTP é acessível tanto via browser quanto via outra instância do Engine. Quando a conexão for de Engine para Engine, o protocolo usado na comunicação é o IAP sobre HTTP. Se a conexão for feita de Browser para Engine, o protocolo será o HTTP.
O Scheduler é o agendador de tarefas. Uma tarefa nada mais é do que a programação de execução de um script da Virtual File System.
Local Cache é um banco de dados disponível em cada instância do Engine que guarda dados de tabelas cadastrais do banco de dados, tabelas de movimentação não estão no cache local. O Local Cache é sincronizado com o banco de dados aproximadamente a cada 30 segundos.
A caixa Native Objects, no infográfico acima, representa os objetos nativos publicados no ambiente iJavaScript do servidor. São exemplos de objetos nativos: DataSet, Connection, Request, Response, etc.
Client e servidor de aplicativo
O Engine pode ser configurado como um servidor de aplicativo, assumindo a função de se conectar com o banco de dados para responder às requisições de outros Engines (clientes), seja para consulta e gravação de dados, agendar e realizar a execução de scripts, enviar emails, entre outros.
A conexão com o banco de dados ocorre através de drivers próprios, ou seja, a própria DLL cliente de cada SGBD é utilizada para um acesso mais otimizado.
Servidor HTTP
O Engine é um servidor web e, assim, responde às requisições feitas através de um navegador, como o Chrome, Firefox, Safari e Edge.
O Engine implementa os protocolos HTTP 1.1 diretamente sobre TCP/IP, sem nenhuma outra camada de pacote de software entre eles.
Configurações, estatísticas e informações de desempenho estão disponíveis no Servidor HTTP através de qualquer browser.
Quando o Engine está atuando como um servidor HTTP e perde a conexão com seu Servidor de Aplicação, ele ainda pode atender requisições dos browsers.
Caso o desenvolvedor tenha produzido códigos especiais para situações em que se esteja off-line, algumas operações podem ser concluídas de forma transparente. Exemplo: um usuário, fornecendo informações transacionais que não necessitem ser checadas em um servidor de banco de dados central, pode inserir todas as edições no Scheduler do Sistema, que irá salvá-las localmente até que a conexão seja restabelecida. Neste momento, as edições salvas são submetidas ao servidor central para gravação no banco de dados.
A integração do servidor HTTP e de aplicação, juntamente com suas características de funcionamento distribuído, permite que algumas aplicações possam operar ininterruptamente durante uma queda na conexão com o SGBD.
Topologia cliente X servidor
Conforme vimos, a comunicação com o Engine se dá através de um navegador web (servidor HTTP) ou de um outro Engine (servidor de aplicativo). A comunicação com um navegador web é feita através do protocolo HTTP. Já a comunicação com um Engine é feita através de um protocolo proprietário IAP sobre HTTP.
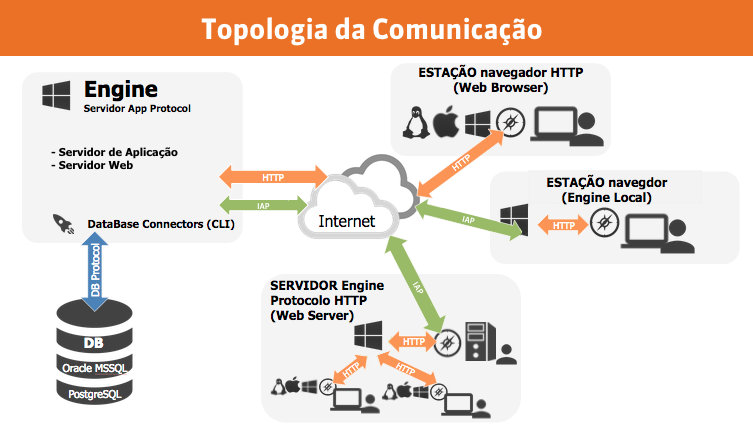
Como podemos ver, o Engine possui a estrutura de um servidor central e clientes que podem também ter um servidor ou podem simplesmente acessar o servidor central através de um navegador web.
No servidor central, deve estar configurado o domínio a ser acessado e o banco de dados. Apenas o servidor central fará conexão direta com o banco de dados.
Uma empresa com um Engine configurado como servidor de borda, comunicando-se com o servidor central, visa maior desempenho na utilização da ferramenta. Isso ocorre, pois haverá um cache nesse servidor de borda, agilizando o acesso ao dado. Essa configuração serve também para “isolar” o funcionamento da rede em um determinado ambiente. Exemplo: um cliente com duas filiais tem um servidor central e, em cada uma dessas filiais, há um Engine de borda. O funcionamento desses Engines de borda será independente em cada filial, sendo sempre sincronizado com o servidor central.
Cache de dados
O cache local é um banco de dados local embutido no Engine. Este banco contém a estrutura e os dados de tabelas previamente selecionadas pelo desenvolvedor da aplicação. Geralmente, estas tabelas são muito acessadas para leitura e recebem um número pequeno de atualizações (inserções, atualizações e deleções). Em nosso sistema, este tipo de tabela é entendida, de uma forma geral, como uma tabela cadastral. Exemplos de dados desta natureza são: Clientes, Produtos, Fornecedores, Empregados, Máquinas, outras tabelas pequenas, etc.
Para manter o cache local sempre sincronizado com o banco de dados, há uma execução independente que é ativada depois que uma requisição é feita ao Engine servidor. Isto ocorre em períodos de aproximadamente 30 segundos.
A sincronização do cache pode ocorrer implícita ou explicitamente. A sincronização implícita ocorre quando um programa referencia um conteúdo (chave) que não está em cache. Explicitamente, a sincronização ocorre quando o programa executa um método específico para atualização do cache.
A disponibilidade destes dados para o Engine permite a composição de conteúdo HTML dinâmico sem precisar acessar o servidor de banco de dados. Isto se reverte em excelente desempenho na entrega de códigos HTML que estejam com dados em cache.
O desenvolvedor pode ainda criar consultas ao servidor de banco de dados, sem realizar joins a estas tabelas do cache. Isto minimiza o uso de largura de banda, visto que nenhuma das informações de cache precisam ser transferidas.
O cache local também permite que o desenvolvedor crie índices cruzados. Com isso, ele poderá criar índices em uma tabela que, de forma transparente, referenciem dados de uma outra tabela.
Interpretador javaScript - iJavascript
A linguagem iJavascript é uma rápida e poderosa implementação do JavaScript.
A linguagem Javascript é de fácil aprendizagem e está disponível em qualquer browser moderno, por isso é possível compartilhar alguns códigos e bibliotecas de forma transparente entre browsers e o Engine.
Seguem alguns pontos que merecem destaque quanto à iJavascript:
- O acesso ao cache local é feito de forma fácil e transparente;
- São usados métodos especiais para controlar a conversão de strings HTML e strings SQL: toHtmlString() e toSqlString();
- Possui suporte ao conceito de módulos JavaScript, assim como métodos de injeção de scripts (__include e __includeOnce), permitindo a organização estruturada dos códigos-fonte;
- Com o suporte ao RMI (Remote Method Invocation), do browser para o Servidor HTTP do Engine, o navegador não precisará recarregar as páginas que contenham atualizações dinâmicas (AJAX).
Produtos
No Engine, há o conceito de produto que está associado a cada script, registro ou classe inserida. Ao se inserir um registro no banco de dados, ele recebe automaticamente uma chave única dentro do Sistema. Cada tabela do sistema tem uma coluna chamada CHAVE ou iKey. Esta chave é o identificador único do registro que a contém.
Um produto é o que o cliente irá adquirir a fim de utilizar o sistema, pois ao ter uma licença de um produto, ele tem todas as funcionalidades existente naquele produto.
Um produto pode ser entendido como uma das faixas de chaves especificadas em nosso cadastro, ou seja, em nossa tabela iLicense. Para cada produto neste cadastro, as chaves pertencentes a ela são definidas em dois grupos. O primeiro grupo de chaves é lido a partir de uma chave inicial e uma quantidade de chaves a partir dessa chave inicial. O segundo grupo associado a esta faixa, é uma lista de diversas chaves que não estão no primeiro grupo.
Chave negativa
Chaves negativas são as chaves que pertencem aos produtos existentes no sistema, ou seja, produtos definidos pela própria fornecedora da plataforma. Em sendo um registro de chave negativa, é potencialmente eleito para participar de um processo de atualização entre duas bases de dados. Em outras palavras, apenas registros de chave negativa podem ser enviados a outras bases de dados.
Chave custom
Existe uma faixa especial de chaves negativas. Esta faixa é de um produto que leva o nome CUSTOM, cujo mantenedor é o próprio cliente. A base geradora do produto CUSTOM deve ser a base de desenvolvimento do cliente e deve ser única. Como é também um grupo de chaves negativas, o produto CUSTOM é portável entre as demais bases do cliente. A propósito, a portabilidade dos registros é a motivação primária da criação de chaves negativas.
Chave positiva
Registros com chave positiva são considerados sem produto. Esses registros não podem ser exportados entre as bases, uma vez que, sendo positiva, essa chave já pode ter sido utilizada na outra base, causando uma referência múltipla àquela chave. Registros de chave positiva são comumente registros relativos aos dados propriamente ditos, ou seja, cadastros, vendas, movimentações financeiras, movimentações do estoque, etc. Dessa forma, podemos entender facilmente que tais dados não são migráveis.
Virtual File System - VFS
No sistema, podemos criar arquivos e diretórios em uma estrutura chamada Virtual File System (Sistema de Arquivos Virtual) ou simplesmente VFS. Na VFS, armazenamos todos os diretórios e arquivos necessários para a execução das aplicações executadas no Web Framework. A utilização de um Virtual File System faz com que a aplicação cliente não precise saber detalhes sobre a implementação real do sistema de arquivos. Dessa forma, em nosso sistema, o desenvolvedor terá uma maneira única e centralizada de acessar os arquivos desejados.
A VFS foi criada com o objetivo de abstrair o desenvolvedor do local onde de fato estão armazenados os arquivos. Isto simplifica o desenvolvimento ao garantir que todos os caminhos dos arquivos são iguais em todas as instalações do sistema e que todos os diretórios e arquivos necessários serão automaticamente distribuídos e atualizados em cada servidor instalado.
O modelo de segurança também se torna mais simples e robusto com o conceito da VFS. Isso ocorre pois, ao conceder permissões aos arquivos e diretórios da VFS, evitamos o uso do sistema de permissões nativo do sistema operacional. Dessa forma, também evitamos as diferenças e incompatibilidades existentes entre os sistemas operacionais suportados pelo Engine.
A VFS encontra-se no banco de dados e é representada por uma tabela de nome iVfs. Apesar de estar no banco de dados, toda a tabela iVfs também se encontra no sistema de arquivo local de cada máquina onde há um Engine instalado. Cada registro desta tabela tem, a exemplo de todas as demais tabelas do sistema, um identificador único para todo o sistema. O identificador único fica no campo CHAVE de cada tabela e, nas tabelas de infraestrutura do sistema, este campo leva o nome iKey.
Os arquivos e diretórios da VFS podem ser editados diretamente no IDE do Engine ou no VS Code. A exemplo de um sistema de arquivos tradicional, nós também controlamos os arquivos através de seu tipo, ou seja, sua extensão. Para tanto, temos uma tabela com os tipos e subtipos válidos para os arquivos de nossa VFS.
Mime-Types
Um mime-type é um método utilizado pelos browsers para associar arquivos de um certo tipo com uma determinada aplicação auxiliar.
Mime-types comuns no Engine:
| Extensão | Nome | Utilização |
|---|---|---|
| .ip | x-process | Definir um processo |
| .il | x-layout | Definir um relatório |
| .ijs | x-javascript | Definir um script em iJavaScript (classes, funções). Executado no lado do servidor. |
| .iejs | x-embedded-javascript | Definir um script em iJavaScript que também tenha código HTML. Executado no lado do servidor. |
| .ic | x-class | Definir a estrutura de uma classe. |
| .view | x-view | Definir a visualização de uma classe. |
| .model | x-model | Definir o modelo de uma classe. |
| .config | x-config | Definir a configuração de uma classe. |
| .is | x-startup | Definir execuções na inicialização da sessão. |
| .if | x-find | Definir algoritmo de busca em uma determinada classe. (Utilizado em lookups) |
| .iat | x-aggregate-table | Definir a estrutura da tabela de agregação |
| .ids | x-datasource | Definir uma fonte de dados com filtros e colunas. |
| .idsq | x-ienginedatasourcequery | Definir consultas no IDS. |
| .idsv | x-ienginedatasourcequeryview | Definir como será a visão das consultas. Atualmente API de IDSV para o SimpleLayout. |
Atualização
Ao alterar um registro na tabela iVfs, é possível enviá-lo para diversas bases. Isso só é possível para os scripts que são de produto, ou seja, que são de chave negativa.
Integrated Development Environment - IDE
A criação e edição de scripts são realizadas no IDE do Engine.
O IDE do Engine permite ao desenvolvedor:
- Visualizar, criar, alterar ou excluir diretórios/classes;
- Visualizar, criar, alterar ou excluir arquivos;
- Executar comandos SQLs no banco de dados;
- Executar scripts JavaScript em um console;
- Depurar códigos JavaScript.
Ao iniciar o IDE pela primeira vez, você poderá observar dois tipos de guia:
- IDE: para criar, alterar e excluir os diretórios e arquivos;
- iDBC SQL: para executar consultas no banco de dados e executar códigos JavaScript; Para abrir novas guias, utilize a opção do menu “Show > New tab”, ou pressione o atalho Ctrl + N. Esta opção irá criar uma nova guia do mesmo tipo da ativa, ou seja, se você estiver em uma guia IDE, será criada uma nova guia IDE, e se estiver na iDBC SQL, será criada uma do mesmo tipo.
No lado esquerdo temos uma árvore com os diretórios do sistema. No lado direito, é exibida uma grade com os arquivos do diretório selecionado, no caso o diretório Raiz.
Na árvore de diretórios, podemos pressionar o botão direito sobre um diretório para abrir um menu com as opções:
- Inserir uma novo diretório, filho do selecionado;
- Excluir o diretório selecionado, caso o mesmo esteja vazio;
- Renomear o diretório selecionado;
- Mover o diretório selecionado;
- Exibir os conteúdos dos diretórios filhos. Ao selecionar esta opção, a grade de arquivos irá exibir os arquivos do diretório selecionado e de todos os diretórios filhos do mesmo. Selecionar esta opção no diretório Raiz permite visualizar todos os arquivos do sistema;
- Copiar a chave do diretório para a área de transferência.
Ao lado da árvore de diretórios, podemos observar a guia Contents exibindo os arquivos do diretório selecionado. São exibidos os seguintes campos:
- Nome do arquivo;
- Tipo do arquivo, determinado automaticamente pela extensão do nome do arquivo, seguindo a nomenclatura do MIME media type.
- Produto, indicando de qual produto este arquivo faz parte.
- Conteúdo do arquivo;
- URL, caminho completo do arquivo.
Também existem botões que permitem navegar nos registros da grade da guia Contents, inserir, excluir arquivos, confirmar ou cancelar as alterações realizadas.
OBS: Ao criar um script verificar em qual produto foi criado, pois pode interferir em um upgrade para uma base. A forma de definir o produto para criação de script e classe no IDE é: Tools > Product to create keys > Escolher o produto. “No product (positive key)” a chave será positiva e não irá interferir em upgrade, será somente um registro da base em que foi criado.
Para editar o conteúdo de um arquivo, podemos utilizar a guia Edit. Ela irá exibir o conteúdo do arquivo posicionado em um editor com destaque de sintaxe e facilidades para o desenvolvedor. Após a edição, podemos confirmar a alterando pressionando no botão Confirmar da barra de navegação de arquivos ou utilizando o atalho Ctrl + S.
A guia History permite visualizar as alterações realizadas no arquivo posicionado, indicando a data, hora e o usuário que alterou o arquivo. Nesta grade podemos selecionar os registros com as alterações e pressionar o botão direito do mouse para abrir as opções:
- Exibir diferenças: será aberto o WinMerge, caso esteja instalado, exibindo as alterações realizadas nos registros selecionados;
- Refazer a alteração
- Desfazer a alteração
Por último podemos observar a barra de estados no final da janela. Ela exibe as seguintes informações:
- Nome da base de dados e a porta em o Engine está servindo.
- Nome do usuário que realizou o login no IDE.
- Posição e total de registros apresentados na grade de arquivos.
- Chave do diretório selecionado e o produto de qual faz parte.
iDBC
Ao acessar o menu “Show > iDBC SQL”, é aberta uma nova aba onde é possível realizar testes e já verificar o resultado. Uma espécie de console para utilizar o iJavaScript.
No iDBC é possível fazer consultas ao banco de dados, testar funções a serem inseridas em um objeto, enfim, qualquer execução iJavaScript que se deseje fazer.
A interface é composta de um editor de scripts JavaScript e uma grade que exibe o último resultado do script.
Ao lado do botão Browser, temos os seguintes botões:
- Abrir um script gravado no disco local;
- Gravar um script no disco local;
- Executar o script;
- Abortar execução do script;
- Gravar no banco de dados as alterações realizadas no DataSet resultado do script.
Ao criar uma nova guia iDBC sql é sugerido um script para realizar uma query no banco de dados e um loop para manipulação do resultado da query. Por último, o resultado é deixado na pilha do script para que seja exibido na grade. Apesar desta sugestão ser o uso mais frequente da guia iDBC SQL, ela pode ser utilizada para executar qualquer script JavaScript. Este é um recurso muito útil para testar pequenos trechos de códigos.
Por último temos a barra de estados no final da janela. Ela exibe as seguintes informações:
- Nome da base de dados e a porta em o Engine está servindo.
- Nome do usuário que realizou o login no IDE.
- Posição e total de registros apresentados na grade resultado.
- Informações do registro identificado pela chave do campo com foco. Este recurso funciona apenas para tabelas armazenadas no cache do Engine.
Debugger
Por padrão o debug fica desativado por deixar a execução dos scripts mais lenta, sendo necessário o seguinte procedimento para ativá-lo:
- Com o Engine em funcionamento, no browser digitar o endereço do manage do Engine que se deseja
ativar o debug (com o funcionamento local, seria por exemplo:
http://127.0.0.1/manage); - Informar usuário e senha;
- Ir em “Configuration";
- Clicar em “General";
- Marcar a opção “JavaScript Debugger Enabled";
- Clicar em “Save";
- Reiniciar o Engine;
A forma de inserção de breakpoint nos scripts é diferente dos demais IDEs. É necessário inserir a palavra reservada “debugger”, que funcionará como breakpoint. É importante colocar essa palavra reservada dentro de uma condição para o usuário que estará executando o processo, pois se não o debugger será iniciado para quem estiver executando o processo e estiver com o debugger ativo. Exemplo:
function exemplo() {
if (session.userKey === /* Usuário que iniciará o modo debug */) {
debugger;
// some code...
}
}
OBS: É importante que em testes de performance o debugger seja desativado pois além da execução dos scripts ser mais lenta, há um aumento no consumo de memória.
Hierarquia de diretórios
No diretório raiz da VFS temos 4 diretórios que merecem ser destacados:
- Products: diretório onde são armazenados os códigos fontes dos processos, relatórios e bibliotecas utilizadas pelos módulos do sistema.
- Dados: diretório onde são declaradas as tabelas do sistema.
- Configuração: diretório onde são armazenados configurações globais a todos os módulos do sistema. Configurações específicas são armazenadas em diretórios específicos do módulo ou do produto.
- Menu: diretório onde são declarados os módulos do sistema navegáveis a partir do menu principal.
Products
Por padronização, criamos um diretório filho de products para cada produto do sistema e um diretório especial chamado custom para os processos e relatórios desenvolvidos pelos desenvolvedores usuários do sistema. A árvore de produtos possui uma divisão forte de paternidade de códigos, segmentada em produtos e módulos do sistema.
Filho de cada subdiretório de products, recomendamos a seguinte árvore de subdiretórios:
- modules: onde podem definidos módulos do produto, com processos e relatórios;
- library: bibliotecas utilizadas pelos processos e relatórios dos módulos do produto;
- tests: onde serão armazenados os testes unitários do produto;
- dataSources: onde são definidas as fontes de dados para os relatórios do produto;
- configuration: configurações dos módulos do produto realizadas através de scripts JavaScript.
Dados
Alguns diretórios da VFS possuem uma finalidade complementar de definir uma tabela no banco de dados e uma hierarquia de classe de dados. Por este motivo, também chamamos os diretórios de classes de dados. No sistema o termo diretório e classe são sinônimos.
O modelo de dados é compartilhado entre todos os produtos e módulos do sistema, portanto nos subdiretórios de Dados não deve haver divisão por módulos ou produtos. Os nomes dos diretórios/classes não devem fazer menção ao módulo em que são utilizados e sim à finalidade daquela informação. A árvore de classes de Dados busca a integração e reuso de conceitos, ao contrário da árvore de Produtos que busca definir fortemente uma paternidade.
Configurações
Algumas configurações do sistema são realizadas através de scripts JavaScript e o diretório Configurações armazena as configurações globais à todo o sistema. As configurações específicas de um produto ou módulo devem ser criadas no subdiretório configuration do produto.
No diretório Configurações, existem 2 diretórios importantes que são:
- Inicialização da Sessão: contém scripts que serão executados quando um usuário inicia uma nova sessão no Web Framework;
- Inicialização do Engine: contém scripts que serão executados na inicialização do Engine.
Menu
Um diretório para ser exibido no menu deve ser navegável, uma propriedade do diretório definida através de um x-class ou x-view. O conteúdo deste arquivo deve conter:
this.canNavigate = true;
Esta propriedade determina que o diretório é navegável, sendo exibido no menu principal. O primeiro nível de diretórios navegáveis exibidos no menu são chamados de módulos do sistema.
Processos e relatórios devem ser criados dentro dos módulos, caso contrário eles nunca serão exibidos no menu.
Protocolo de Comunicação IAP
O IAP é um protocolo de comunicação especial usado para controlar as comunicações entre aplicativos Engine e implementado sobre os protocolos HTTP ou HTTPS. A comunicação é realizada em blocos de dados, permitindo ao Engine, que atua no modo de servidor de aplicações, controlar diversos canais de comunicação simultâneos.
Estes blocos de dados são compactados utilizando-se o algoritmo BitStreamer e depois o algoritmo de compressão Zlib (usado no WinZip e PkZip). Com isto, garante-se a melhor utilização da largura de banda atual. Após a compressão, os dados são então criptografados e enviados.
O algoritmo BitStreamer é uma rotina de compressão especial que analisa informações de datasets, eliminando redundâncias que passariam despercebidamente pelo algoritmo de compressão Zlib:
- Sequências de registros com campos inalterados;
- Incrementos entre campos de registros;
- Salto pelo número de campos inalterados;
- Transformações em sequências (streams) de bits;
Conector Engine X Engine
A comunicação entre um Engine cliente e seu Engine servidor (servidor de aplicação) é feita através do objeto connection. Este objeto é uma instância nativa da classe Connection.
Objetos da classe Connection representam conexões IAP (protocolo acima descrito) entre aplicativos Engine.
Algumas das utilidades de um objeto da classe Connection:
- Solicitar uma execução de script ao Engine servidor. Isso geralmente é feito quando o processamento precisa ser centralizado, quer seja para um melhor aproveitamento dos recursos envolvidos, quer seja para processamento em background, liberando a aplicação cliente para continuar no fluxo de um atendimento mais prioritário;
- Verificar se a conexão com o servidor está online;
- Verificar a versão do Engine em uso;
- Obter data e hora do servidor;
- Agendar o envio de um email pelo servidor;
- Conectar um engine a outro que não seja o seu Engine servidor;
Conector Engine X Banco de Dados
Para o acesso ao banco de dados, o Engine disponibiliza um objeto nativo chamado database. Este objeto é uma instância da classe DataBaseProxy e está conectado ao Engine servidor, que por sua vez cede o acesso ao banco de dados.
O database objeto oferece dois métodos principais de comunicação com o banco de dados:
database.query(): Utilizado para enviar uma ou mais queries de SELECT ao banco de dados. Este método retorna um ou mais DataSets com o resultado da consulta.database.executeSQL(): Através deste método, podemos enviar comandos DML e DDL que nada retornam. Este método é útil quando se deseja enviar comandos do tipo INSERT, DELETE, CREATE, DROP, etc.
Caso o SGBD a ser consultado não seja o que está associado ao Engine, podemos utilizar a classe DataBaseProxy e criar uma conexão a outro banco de dados. Estas conexões são feitas sempre através de um Engine servidor conectado ao banco de dados que se deseja acessar.
Manage
O Manage é uma interface de gerenciamento que permite configurar e monitorar o funcionamento de uma instância específica do Engine. Nela é possível configurar se o Engine atuará como um servidor de aplicação ou de borda, definir as regras de direcionamento de arquivos de logs, habilitar a depuração de códigos JavaScript, monitorar as requisições HTTP e o consumo de memória do sistema, dentre outras funcionalidades.
Abaixo segue uma breve descrição conceitual sobre cada item disponível no menu desta interface. Para saber mais detalhes sobre a configuração destes itens, favor acessar a página Configuração do Engine.
Configuration
Esta é a principal seção de configuração. Aqui definimos diversos parâmetros como senha de acesso ao Manage, porta em que a aplicação será disponibilizada, dados para a conexão com o SGBD, etc. A seguir, listamos cada opção disponível nesta seção, bem como uma breve explicação sobre o item.
- General - Definem parâmetros básicos como: mudança da senha e nome do usuário para acessar o manage, habilitar o uso do debugger, habilitar o log do profiler, etc.
- Domains - É onde se configura qual servidor o engine está acessando. Já é preenchido automaticamente se você definiu isso nos parâmetros do executável.
- Databases - Aqui é onde se configura o acesso ao banco de dados associado ao engine. A configuração dependerá de qual SGBD está em uso. Nesta área, definimos dados como tipo do banco de dados (ORACLE, MSSQL, POSTGRESQL), usuário e senha para acesso ao banco, número máximo de conexões simultâneas ao banco de dados, etc.
- Others - Definição de algumas configurações mais técnicas. Para mais informações, acesse essa opção e observe um texto explicativo para cada configuração em uso.
- Ports - Local onde configuramos as portas do engine, em qual porta ele vai ocupar quando for iniciado. Se a mesma estiver ocupada ele tentará ocupar a próxima porta. Nessa configuração só é necessário indicar o número da porta, o protocolo de comunicação e se a porta será habilitada ou não.
Requests
Controle de todas as conexões/requisições do engine. Através do requests, você pode abortar algumas queries, analisar o profiler associado a cada requisição, ver o tempo das requisições e, em alguns casos, quem as disparou, etc.
Sessions
Esta opção é útil no monitoramento das sessões criadas no engine. É uma importante ferramenta que pode ser usada nos diagnósticos de erros e consumo excessivo de memória.
Memory
Mostra gráficos que representam o consumo de memória do engine em determinados períodos acumulados: ultima hora, ultimas 24 horas, últimos 7 dias e últimos 60 dias.
Profiler
Exibe o log do profiler se o mesmo tiver sido habilitado através do menu Configuration/General. O log do profiler é um detalhamento quantitativo sobre informações relativas ao desempenho da execução de algumas rotinas. Tais rotinas foram previamente preparadas para ter o detalhamento do profiler.
Log
Aqui você pode visualizar os logs do engine e fazer novas configurações de logs. São várias as categorias de log e cada uma traz informações a ela relacionada. Como exemplo de categorias, temos log do: scheduler, dbCache, application, network, etc.
Agendador de scripts (Scheduler)
Através do Scheduler é possível agendar uma execução de um script JavaScript em um determinado momento ou numa determina frequência. É um recurso interessante para automatizar a execução de processos demorados e ou frequentes e que precisam ser disparados em horários específicos.
Usando o Scheduler é possível criar aplicação com execução de scripts assíncronos, este recurso permite construir interfaces mais rápidas deixando alguns processos que não precisarão mais de interação com o usuário executando em background.
Tabelas de Agregação de Dados
O Engine possui uma estrutura que mantem dados agregados (apenas de soma) de uma determinada tabela. Essa estrutura proporciona ganhos de performance no desenvolvimento de relatórios bem como em validações de saldos em operações (ex.: validação de estoque).
Segurança dos Dados
O Engine fornece uma estrutura de usuários e grupos de usuários que permite definições de permissões aos dados. Os tipos de permissões padrões são: ver, inserir, alterar e excluir pelo tipo do dado. Essa estrutura permite ser estendida podendo incluir outros tipos de permissões como: aprovação, criar pedido, cancelar nota fiscal, etc.