Análise de desempenho
Durante o desenvolvimento de um novo processo ou relatório temos como objetivo criar códigos com as seguintes propriedades:
- Acurácia: as informações exibidas e manipuladas devem ser corretas;
- Legibilidade: o código fonte deve ser construído de tal forma que um outro desenvolvedor que não participou da sua concepção possa compreendê-lo e alterá-lo com segurança e produtividade;
- Eficiência: o processo ou relatório deve ser executado em tempo satisfatório na perspectiva do usuário.
Para alcançar cada uma destas propriedades, existem métodos e ferramentas que auxiliam o desenvolvedor.
O objetivo deste documento é explicar o funcionamento do Profiler, uma ferramenta que auxilia o processo de otimização de códigos JavaScript, tornando-os mais eficientes.
Não é o objetivo deste documento apresentar técnicas de otimização de código, de instruções SQL ou explicações teóricas sobre custo ou complexidade.
Onde está o problema?
Ao observar a execução de um processo ou relatório com desempenho abaixo do aceitável, podemos facilmente concluir que o sistema está lento. Esta observação é genérica demais para ser útil, pois não iremos otimizar o sistema inteiro e sim alguns trechos ineficientes do sistema.
Identificar os códigos responsáveis por um baixo desempenho não é uma tarefa trivial, pois existem custos implícitos de difícil observação durante a leitura de um código. Um relatório, por mais simples que seja, realiza:
- Acesso ao cache local;
- Transferência de dados através da rede;
- Consultas no banco de dados;
- Uso de bibliotecas cujo código é desconhecido pelo desenvolvedor do relatório;
São muitos os fatores que podem afetar o desempenho de um processo ou relatório, sendo improdutivo tentar solucionar o problema utilizando apenas a intuição e otimizações na estratégia de tentativa e erro. O desenvolvedor precisa de informações que orientem a sua atenção para os códigos responsáveis pelo baixo desempenho.
Para gerar estas informações existem ferramentas chamadas de Profiler. Estas ferramentas analisam o desempenho de um processo através de técnicas que possibilitam uma análise detalhada dos custos internos de um processo, sendo a instrumentação e a amostragem as mais conhecidas e utilizadas.
O Nginstack possui uma ferramenta de Profiler baseada em instrumentação manual do código fonte. Esta ferramenta pode ser utilizada através da classe Profiler, responsável por realizar a instrumentação e pela geração de relatórios contendo as informações coletadas.
Configurando o Profiler
Antes de ser utilizado, o Profiler deve ser habilitado através da opção “Profiler Enabled” existente na página “Configuration > General” do Manage.
A opção “Min RunTime to Log Profiler” configura a gravação automática das estatísticas de todas as operações executadas pelo iEngine em um arquivo de log, o “profiler.log”. Todas as operações com tempo de execução superior ao valor informado serão gravadas. Esta configuração é extremamente importante para analisar um problema de baixo desempenho de difícil reprodução. Utilizando esta opção, com um tempo inferior ao observado pelo usuário, se garante a gravação das estatísticas para uma posterior análise.
Para se obter melhores resultados na análise, ferramentas e códigos utilizados exclusivamente para depuração devem ser desativados, pois eles podem elevar os tempos de execução observados. O uso do depurador torna a execução do código mais lenta e as paradas são totalizadas como tempo de execução dos métodos depurados. Logs são escritos no disco, operação que pode ser mais demorada do que o próprio método analisado.
Portanto é recomendado que sejam desligados o depurador de códigos JavaScript e os Loggers que estejam com prioridade “DEBUG”. Para desativar o depurador, desmarque a opção “JavaScript Debugger Enabled (requires restart)" existente na página “Configuration > General” do Manage. Para desativar os Loggers, verifique se o campo “Custom” existente na página “Log > Configuration” do Manage está vazia.
Instrumentação do código fonte
Instrumentar o código fonte nada mais é que adicionar códigos que meçam o tempo de execução ou alocação de memória do código instrumentado. No sistema, a instrumentação pode ser realizada de forma automática pelo Engine, ou podem ser instrumentados trechos específicos de códigos manualmente.
Profiler automático de funções
É possível mensurar automaticamente todas as chamadas à funções do sistema, sem a necessidade de alterar o código para incluir as invocações ao objeto profiler. Para ativar essa funcionalidade, marque a opção “Automatic Profiler Active” existente na página “Configuration > General” do Manage. A opção “Profiler Enabled” também deve estar habilitada.
Importante: o profiler automático registra a execução de todas as funções JavaScript, requerendo uma quantidade significativa de memória para controlar esses registros. Essa configuração não deve estar ativa em servidores de produção ou em servidores de testes que possuem uma quantidade de usuários simultâneos expressiva. É recomendado que ela seja desativada logo após a análise de desempenho.
Instrumentação manual de código
Tendo em vista que o sistema pode gerar a instrumentação automática de todas as funções JavaScript, a instrumentação manual é um recurso que deve ser reservado apenas para alguns cenários específicos de uso:
- Para avaliar o desempenho de códigos que não são facilmente identificáveis pelas
funções instrumentadas de forma automática, como é caso das funções anônimas, dos códigos
executados por meio do
eval()ou trechos específicos de funções muito complexas. - Coletar detalhes adicionais que não são capturados pela instrumentação automática, como expressões SQL executadas ou os parâmetros recebidos pelas funções.
- Instrumentar códigos que são relevantes de serem observados e monitorados nos servidores de produção, mesmo quando uma análise de desempenho não está sendo realizada.
A instrumentação manual é realizada pelos métodos startOperation e endOperation da classe
Profiler. Uma instância dessa classe é publicada pelo Engine via variável global profiler,
portanto não é necessária a criação manual de uma nova instância. Em módulos, é recomendado que
o profiler seja obtido conforme exemplo abaixo:
const profiler = require('@nginstack/engine/lib/profiler/Profiler').getInstance();
profiler.startOperation('Código analisado', '', true);
try {
code();
} finally {
profiler.endOperation();
}
Os métodos startOperation e endOperation possuem a seguinte assinatura:
profiler.startOperation(name, details, sumInteractions)profiler.endOperation(details)
O parâmetro details tem a utilidade de adicionar informações relevantes ao código analisado, como
os parâmetros recebidos por uma função. O sumInteractions determina que as várias execuções do
código instrumentado devem ser totalizadas.
Em uma primeira análise, é recomendado que o parâmetro details não seja utilizado e que
a opção sumInteractions seja ativada, como no exemplo acima. O objetivo é gerar uma visão
mais sintética que possibilite observar quais códigos são relevantes e merecem ser
detalhados com mais instrumentação.
Ao concluir a análise de desempenho, deve-se remover toda a instrumentação manual que não gera valor no monitoramento dos servidores de produção que estejam com a opção Profiler Enabled ativa.
Análise do Log do Profiler
As informações coletadas pela instrumentação podem ser obtidas através dos métodos
getHtmlStatistics() e getTxtStatistics() do Profiler. Estes métodos geram um relatório com os
tempos de execução e alocação de memória de todos os códigos instrumentados.
Apesar de legível, o relatório não permite uma análise manual produtiva, pois o volume de informações normalmente é elevado. Para simplificar esta análise existe o processo “Desenvolvimento > Análise do Log do Profiler” que apresenta as informações coletadas pelo Profiler em uma visão mais sintética e útil para o desenvolvedor.
Este processo permite analisar um resultado contido nos arquivos de log do profiler ou de uma
estatística coletada manualmente pelo desenvolvedor através do método getTxtStatistics().
Normalmente uma otimização necessita de vários ciclos de instrumentação, otimização e análise dos resultados. A forma mais produtiva de reproduzir este ciclo é isolar o código a ser otimizado na guia iDBCsql dentro da seguinte estrutura:
profiler.forcedLog = true;
profiler.startOperation("MyTest");
try {
code();
} finally {
profiler.endOperation();
}
File.fileFromString("c:\Nginstack\profiler.txt", profiler.getTxtStatistics());
Este código gera a cada execução o arquivo “c:\Nginstack\profiler.txt” com as estatísticas coletadas pelo Profiler. O resultado deste arquivo pode ser analisado utilizando a opção “Utilizar arquivo com estatísticas” no processo de análise.
O maior benefício desta abordagem é a velocidade para realizar uma nova análise. Basta executar o script na guia iDBCsql e pressionar o botão “Atualizar” do processo “Análise do Log do Profiler” para visualizar o resultado. Ela elimina a necessidade de fechar a sessão, logar no sistema, entrar no processo ou relatório, preencher variáveis e procurar o resultado no log.
Quando não é possível isolar o código na guia iDBCsql, devemos fazer uso das informações gravadas no log do profiler. Para isto, devemos primeiramente garantir que as estatísticas coletadas durante a execução de um relatório ou processo sejam gravadas no log. Duas alternativas:
Explicitamente indicar no código fonte que o profiler gerado deve ser gravado no log através da
instrução profiler.forcedLog = true. Esta instrução pode estar em qualquer local do código, mas
preferencialmente deve ser adicionada no início.
Configurar a propriedade “Min RunTime to Log Profiler (ms)” do Manage para um valor inferior ao
tempo de execução do processo ou relatório.
Após a execução do processo ou relatório, o resultado do profiler deverá ter sido gravado no log.
Na interface do processo “Análise do Log do Profiler” deverá ser selecionado o arquivo de
profiler. O arquivo de log do dia corrente é o “profiler.log”.
Os arquivos de log do profiler podem conter um volume elevado de informações, portanto é recomendado a utilização dos campos Filtros para conseguir localizar rapidamente as estatísticas desejadas. Uma boa estratégia é pesquisar por um nome de operação utilizada apenas no processo ou relatório analisado.
Após a seleção do arquivo e dos filtros será exibida uma interface com todos os registros do arquivo de log que satisfaçam os filtros informados. Deve ser selecionado o registro desejado pela hora de início e pelo tempo de execução e em seguida pressionado o botão Analisar.
O principal resultado da análise é a grade “Operações Agrupadas por Nome”. Esta grade apresenta os campos:
- Nome: parâmetro “name” informado ao método
Profiler.startOperation. - Quantidade: quantidade total de vezes que o código instrumentado foi executado.
- Tempo c/ filhas: tempo de execução total do código instrumentado.
- Tempo s/ filhas: tempo de execução do código instrumentado desconsiderando os códigos filhos que já possuem instrumentação.
- Tempo das filhas: “Tempo c/ filhas” - “Tempo s/ filhas”.
- Qtd blocos c/ filhas: quantidade total de blocos de memória alocados pelo código instrumentado.
- Qtd blocos s/ filhas: quantidade de blocos de memória alocados pelo código instrumentado desconsiderado as alocações realizadas pelos códigos filhos que já possuem instrumentação.
- Qtd blocos das filhas: “Qtd blocos c/ filhas” - “Qtd blocos s/ filhas”.
O conceito de operação filha, pode ser melhor compreendido através do exemplo abaixo:
profiler.startOperation("MyTest", null, true);
try {
sleep(1000);
test();
} finally {
profiler.endOperation();
}
| Nome | Qtd | T c/ filhas | T s/ filhas | T das filhas | Blocos c/ filhas | Blocos s/ filhas | Blocos das filhas |
|---|---|---|---|---|---|---|---|
| MyTest | 1 | 9999 | 9999 | 0 | 1 | 1 | 0 |
| Executing JavaScript | 1 | 9999 | 0 | 9999 | -1768 | -1769 | 1 |
Ao observar o tempo de execução da operação MyTest, observamos que o tempo total é de aproximadamente 10seg. Não existem códigos filhos que possuam instrumentação, logo temos que olhar o código contido em MyTest para compreender onde está a demora.
Analisando o código, observamos facilmente a explicação para uma demora de 1seg pela execução de
um sleep(). Também podemos concluir que os outros 9 segundos devem estar sendo consumidos pela
função test(). Para confirmar esta suposição, iremos instrumentar a função test(),
como observado no código abaixo:
profiler.startOperation("MyTest", null, true);
try {
sleep(1000);
test();
} finally {
profiler.endOperation();
}
function test() {
profiler.startOperation("test()", null, true);
try {
sleep(9000);
} finally {
profiler.endOperation();
}
}
Abaixo o resultado da análise:
| Nome | Qtd | T c/ filhas | T s/ filhas | T das filhas | Blocos c/ filhas | Blocos s/ filhas | Blocos das filhas |
|---|---|---|---|---|---|---|---|
| test() | 1 | 8999 | 8999 | 0 | 0 | 0 | 0 |
| MyTest | 1 | 9999 | 1000 | 8999 | 1 | 1 | 0 |
| Executing JavaScript | 1 | 9999 | 0 | 9999 | -1768 | -1769 | 1 |
Agora podemos observar que 9 dos 10 segundos de execução de “MyTest” estão sendo consumidos
por test(). Esta função agora merece maior atenção na nossa análise, pois ela é responsável por
90% do tempo de processamento.
Ao analisar o código da função test, percebemos que os 9 segundos estão sendo consumidos por um
sleep, o que justifique a demora, não havendo mais necessidade de buscar operações filhas.
Encontrando oportunidades de melhoria
A busca por oportunidades de melhorias no código fonte é uma das tarefas mais demoradas em um processo de otimização. Para ser produtivo nesta busca, o desenvolvedor deve interpretar com atenção os campos da grade “Operações agrupadas por nome” para perceber oportunidades de otimização, principalmente os campos Quantidade e Tempo s/ filhas.
Quantidade
A melhor otimização possível é a eliminação de códigos desnecessários e o campo Quantidade é o melhor indicativo de desperdícios. O benefício esperado ao reduzir a quantidade de execuções normalmente é uma redução proporcional do Tempo c/ filhas.
Exemplo: durante a otimização de uma venda se observa que o código new OperacaoPedido() foi
executado 4 vezes e é a operação de maior custo observada na análise. A princípio, apenas uma
execução deveria ser necessária e ao corrigir o processo para realizar apenas uma construção,
se observou que esta operação deixou de ser a de maior custo.
Este tipo de otimização é interessante, pois tornar o código new OperacaoPedido() mais rápido
pode ser uma tarefa complexa. Ao eliminar as chamadas redundantes tornamos este código menos
relevante no tempo total da operação, focando a otimização em outros códigos mais simples e que
trarão maior benefício ao processo de otimização.
A quantidade tem um papel ainda mais importante quando está relacionada a operações que envolvam
I/O. Normalmente as operações de I/O, como disco e rede, têm custos elevados que ocorrem a cada
execução, como o custo de conexão e propagação em operações de socket e o custo do acesso randômico
em operações que utilizam o disco. Estes custos podem ser minimizados realizando leituras em blocos,
ao invés de byte a byte, ou a execução de vários SQL em uma única chamada do método
Database.query().
Tempo s/ filhas
Uma outra estratégia de otimização é dar foco nas operações com maior Tempo s/ filhas. Esta estratégia é boa quando não se conhece o código a ser otimizado a ponto de ser possível criticar se as quantidades de execuções das operações são coerente. Não por acaso, a grade “Operações agrupadas por Nome” é por padrão ordenada para exibir as operações com maior Tempo s/ filhas.
Duas conclusões são possíveis após a análise de um código fonte com elevado Tempo s/ filhas:
- A operação em questão possui um tempo s/ filhas alto, pois executa métodos e funções que não foram instrumentados. Ao adicionar instrumentação nestes códigos, se observa que o custo da operação é reduzido e outras operações passam a ser mais representativas.
- Todos os métodos e funções utilizados na operação já foram instrumentados e o código da operação realmente é responsável pelo tempo observado.
Se chegamos a segunda conclusão, teremos encontrado um bom candidato para a otimização de código e devemos procurar uma forma de torná-lo mais rápido. Técnicas de otimização fogem ao escopo deste documento, mas algumas dicas básicas são:
- Evite pesquisas sequenciais. Estruturas como Arrays ordenados, DataSets e tabelas hashs (propriedades de objetos) permitem pesquisas mais eficientes;
- Evite execução redundante em laços. Códigos contidos em um laço que não tem o resultado alterado durante a execução do laço podem ter o seu cálculo antecipado e armazenado em variáveis.
- Nas consultas ao banco de dados, analise se o plano de execução gerado é adequado. Caso não seja, reveja a expressão SQL até conseguir um bom plano de execução. As vezes é necessária a criação de um novo índice para otimizar uma consulta.
Quando não for possível otimizar um código, avalie a possibilidade de diminuir a quantidade de execuções criando um cache de resultados. O problema desta abordagem é a eventual complexidade de garantir a consistência do cache caso os dados que originaram o cache sejam alterados.
Em alguns cenários é aceitável trabalhar com caches levemente defasados, possibilitando a criação de caches com estratégias de atualização simples e eficientes. Um exemplo desta abordagem é a classe DBCache (o cache local). Os dados contidos no cache podem estar desatualizados em até 1 minuto em relação ao banco de dados. Garantir os dados em cache sempre atualizados exigiria um acesso ao banco de dados a cada acesso ao cache, tornando inviável o uso do cache local.
Boas práticas de instrumentação
Ao iniciar um processo de otimização é importante adicionar instrumentação que englobe toda
a operação analisada. Exemplo: se um relatório está sendo analisado, todo o código contido na
interação “run” deve estar contido dentro de um startOperation() e um endOperation().
Se a execução associada a um botão for lenta, todo o evento onClick ou a interação destino
associada deve ser coberta.
O objetivo desta prática é garantir que o tempo total da operação possa ser observado no resultado da análise e seja comparado com a percepção de tempo do usuário. Se o valor for próximo, significa que o código suspeito realmente é responsável pela demora observada e pode se prosseguir com a investigação. Caso o tempo observado seja muito inferior ao tempo observado pelo usuário, o problema pode estar em códigos executados antes ou depois do código suspeito e neste caso o código que a princípio seria o problema, não merece ser analisado.
Após um processo de otimização é interessante preservar as instrumentações adicionadas, pois em otimizações futuras estas informações já estarão disponíveis sem maiores esforços. A única ressalva é não manter instrumentação em códigos que sejam executados na ordem de milhares de vezes, pois o profiler tem um custo que pode ser maior que o próprio código analisado. Vale ressaltar que este custo é percebido apenas quando o iEngine está com o Profiler habilitado.
Avaliando o custo de execuções remotas
Os métodos da classe Connection e Database possuem um comportamento interessante que merece ser
destacado.
Uma execução remota, como uma consulta ao banco de dados, é uma operação que pode ser observada em 2 etapas na perspectiva do iEngine cliente:
- O envio da expressão SQL para o servidor, observado no profiler como “Writing to TCP/IP socket”;
- A leitura dos registros que foram retornados pelo banco de dados, observado como “Reading from TCP/IP socket”;
No entanto, durante estas 2 etapas, existe o tempo necessário para executar a consulta e o custo de acesso ao banco de dados. Este custo é desconhecido pelo cliente, pois é uma operação que está ocorrendo no iEngine servidor. Na perspectiva do cliente, está ocorrendo apenas uma demora na recepção da resposta. Abaixo um diagrama que ilustra melhor este conceito:
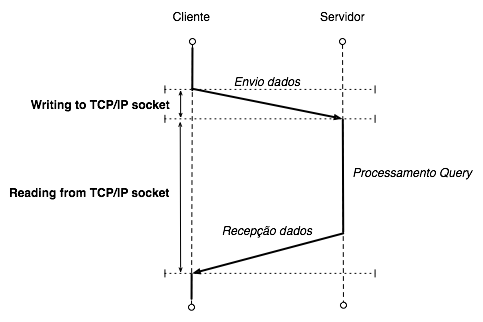
Na perspectiva do iEngine cliente, o tempo da operação “Reading from TCP/IP socket” inclui o tempo do processamento do servidor. Portanto sempre devemos interpretar o tempo desta operação como o custo de transmissão mais o custo de processamento no servidor, este último sendo passível de otimização, como o obtido ao otimizar uma expressão SQL.
Maiores detalhes do que ocorreu durante um “Reading from TCP/IP socket” podem ser obtidos analisando o log do profiler gerado pelo servidor.
Conclusão
O processo de otimização deve ser realizado com técnicas e ferramentas que direcionem o processo para os reais gargalos de performance. A otimização baseada apenas na intuição é improdutiva e ineficiente.
Toda tentativa de otimização necessita de uma medição do tempo de execução anterior e posterior à modificação. Apenas as alterações que gerem ganhos significativos devem ser mantidas, principalmente quando a otimização gera um prejuízo na legibilidade do código.
A ferramenta de Profiler do Nginstack é a principal ferramenta para guiar o desenvolvedor no processo de otimização e saber utilizá-la é fundamental para ser produtivo nesta tarefa.